2020-12-31 13:43:45 来源:投资家网专栏 作者:智能相对论
2020-12-31 13:43:45 来源:投资家网专栏 作者:智能相对论 摘要:AI成了新基建的C位,不论是原本就以AI立身的百度,还是纷纷在技术上加大投入以拥抱新基建的阿里、腾讯等巨头,最近都显出强化AI地位的态势。
文/智能相对论(aixdlun)
作者/叶远风
AI成了新基建的C位,不论是原本就以AI立身的百度,还是纷纷在技术上加大投入以拥抱新基建的阿里、腾讯等巨头,最近都显出强化AI地位的态势。
在AI新基建浪潮下,其背后的动力和“灵魂”——AI数据行业正在快速增长。按照艾瑞咨询《2019年中国人工智能基础数据服务行业研究报告》,预计2025年市场规模将突破113亿元,其中,原本就在AI技术和应用上领先的企业在数据业务上也更为积极。
有人曾称5G是“新基建”的“基建”,是很多新基建项目的前置技术。事实上,以数据众包为代表的AI数据行业,也可以看作AI新基建的“基建”型业务,为各行各业智能化转型提供动能,加速智能经济到来。反过来,当AI新基建蓬勃兴起时,它背后的数据众包产业也面临急速膨胀的市场,这是一片门槛不算高的蓝海,但并非人人都能做得好。
多重因素推动AI数据需求进一步增长
AI从行业架构上分为基础层、技术层、平台层以及应用层。无论是算力、算法、数据都只是在基础层,海量的数据获取和加工是AI发展的基石。
我们通常看到的那些AI智能化应用,在后端首先都需要足够多、足够好的数据对计算机进行训练。
推动基础层AI数据需求进一步增长,肯定来自于更上层的“倒逼”。总体看来,新基建的大背景下,整体AI行业的高速发展驱动了AI数据需求的增长“提速”,而具体来看,又有三重因素:
1、AI应用落地时对数据的强依赖
以人脸识别为例,一般的FaceID已经为人所熟知,其原理,是通过大量数据训练,让算法可以精准为整张脸标记特征,眼睛、鼻子、嘴、颧骨……从而识别不同的人物、确定身份(图片来源:网络):

但是,实际应用落地要想适用面更广,又会有新的麻烦。
例如,疫情期间戴上了口罩,就没办法为鼻子以下的部位做特征标记进行比对。这时候,AI数据的价值就体现出来了,更复杂、更大量的数据训练,让系统在鼻子以上部位能标记出更多、更细致的特征,半边脸就能完全区别出一个人来,甚至有科技公司开发出凭借眼部复杂特征的识别方式。

只有更高质量、更具有丰富度的数据,训练出更细致的特征标注能力,系统识别的能力才会越强。在人脸识别之外,很多AI落地应用也有类似的逻辑。
2、AI应用场景深耕,垂直领域变为数据竞逐
在AI走得更快、更远的一些场景,数据的价值更为明显。
例如,在自动驾驶领域,决定自动驾驶平稳性和安全性的,是系统对路况各种要素的识别,而它们都依赖于前期大量数据训练,给机器标注各要素、教会它识别。
标注得越精细,机器的理解能力就会越强,发生意外的可能性就越低,就像学生学习知识一样,“不知道”的东西越来越少(图片来源:网络)。

国内处在自动驾驶领先位置的百度,首先领先的就是数据,其ApolloScape数据集比Cityscapes、Kitty等同类的自动驾驶数据集大10倍以上,涵盖更复杂的环境、天气和交通状况。
可以说,在那些深耕的场景里,AI的竞逐首先甚至主要就是数据的竞逐,AI新基建的深度落地,离不开对数据的索求。
3、“AI国情”侧重于数据发展
与多数人想象不同的是,同为AI基础层,看起来十分高深的算法,其门槛已经不算高,公开渠道上,论文、开源深度学习框架、各种各样AutoML框架算法,可供获取的很多。
除了百度这样的AI巨头还需要在算法上做一些突破和引领,对多数AI参与者来说,算法已经不是遥不可及。
而正如原南开大学校长龚克所言,中国在核心算法上的优势不算明显,但中国的数据和应用场景可以领先世界。
这方面,AI数据需要的应用采集源(例如人相、交通道路图像等)、劳动力人口、需求市场,中国原本也十分有优势。在这样的“AI国情”下,AI新基建除了保证自有算法能力不被卡脖子,在已有大量落地场景的优势下,大力发展AI数据就顺利成章。
三大痛点,自建团队已并非“AI新基建”最优选择
AI数据的需求方,主要包括AI公司、科技公司、科研机构以及传统意义上的行业企业(手机、汽车、安防等),这个群体越来越庞大。
AI数据的市场供给,主要由企业自建或直接获取外包团队的形式以及供应商组成,而按照艾瑞咨询的报告,供应商模式占比高达79%。
问题在于,为什么需求方们都热衷于选择数据众包这类供应商模式来获得数据,在数据需求庞大的情况下,为什么不自建团队采集和标注数据?这主要基于三个痛点:
1、数据需求的“潮汐现象”
春运期间,铁路运力不够,平时,又大量闲置。
如果自建团队,很多AI需求方将产生与此类似的“潮汐现象”:受自身产品迭代周期的影响,在AI迭代期涌入大量数据需求,团队难以承受;在日常维护期数据需求不是很旺盛,团队又在闲置。
于是,数据供应商就成为弹性投入、增强企业适应力的必然,市场供给的主力军变成各类AI基础数据的服务提供者。
2、数据资源池不足
自建团队往往面临较为严重的数据资源池匮乏问题。举例来说,如果你是一家做与人体有关的图像识别的专业公司,或者需要这样的技术来配合主业,你可能需要寻找不同肤色、不同外形特征的人物做AI数据采集,以提升AI的“认知”能力,而对很多企业而言,除了依赖那些有限的开源数据,没有太多办法。
这方面,专门做数据业务的平台就有明显的资源聚集优势。例如,单就人物图像来说,百度数据众包的数据资源池在国内覆盖30个省份,具备汉族、少数民族采集能力;在国外覆盖22个国家,具备白人、黑人、印第安人等多人种采集能力。
3、数据输出能力的“维度差距”
数据众包平台集中大量地熟悉数据采标业务,已经得到了充足的锻炼,一些平台,例如百度数据众包还对内提供大量数据服务,自2011年起全面支持百度自动驾驶、小度助手等AI业务,它们对于外部需求,在能力上更容易应对。
这本质上体现在通用的“标准化”和专项的“定制化”区别上。AI数据有时候只需要一些标准化的泛化数据,例如道路要素标记,车、路灯、行人、斑马线、双黄线等,有些时候则需要定制化数据,例如专门针对乡村小道的识别,其中可能有野狗、野猫等更复杂的要素。
但这种标准化和定制化只是相对的,对发展往往不够充分的自建平台而言是“定制化”(意味着需要花费大量精力),到了数据众包平台那里,可能只是“标准化”的一部分,像百度数据众包的标注能力已经可以覆盖市95%以上的主要标注场景。
AI新基建对数据采标有三大要求,数据众包都满足了吗?
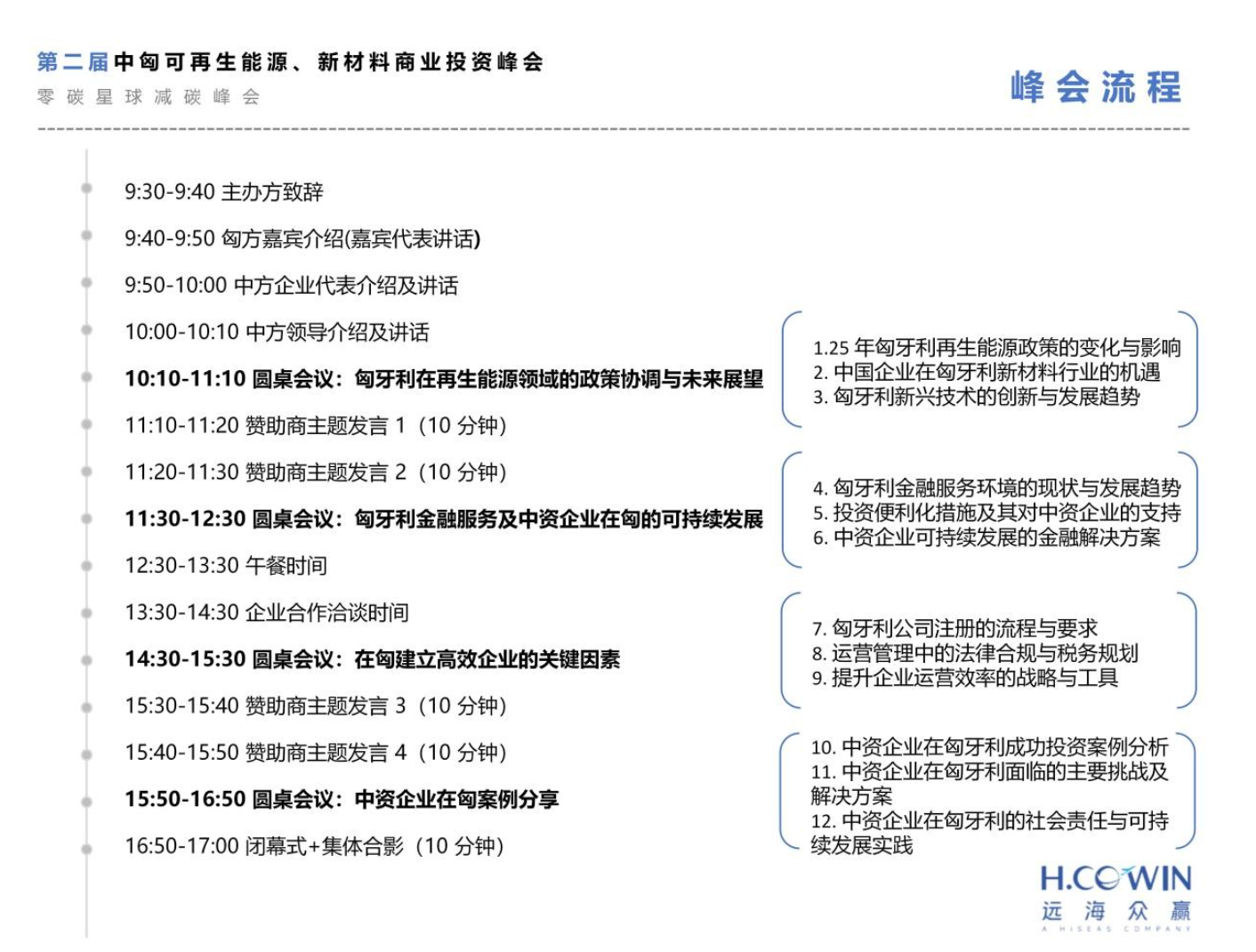
有庞大而快速增长的市场,也有供应商模式相对自建团队的优势,在AI新基建浪潮下,数据众包成为了一门“更好的生意”,这些年也有不断大量的玩家加入(图片来源:艾瑞咨询):
总体而言,最早的玩家大都已经取得较明显的市场优势,例如百度数据众包已经成为在世界范围内采标能力、流程标准化/工具智能化、数据安全等方面都处于领先位置的一站式AI数据服务平台(这与中国AI领先、百度以AI为主战略也有关系),覆盖了智能驾驶、手机、互联网、AI开发者等头部客户;
而新进入者亦有冲劲,像云测数据从云测试转身到AI数据行业,对京东众智、腾讯云数据、龙猫数据等都可能形成冲击。
不过,从需求方的角度看,不论是谁,“一门更好的生意”要坐实,这三大基础要求必须满足。
1、安全:“银行级合规”
AI数据不但是AI新基建的重要驱动力,它也是企业的重要资产,它的泄露和核心算法的泄露都是知识产权的重大损失,没有根本区别。
只不过,算法可以自己蒙头在家管死,而在数据众包市场上,涉及到甲乙方原始数据交接、生产过程及成果交付,这其中存在着许多数据安全的口子。
一旦上升到新基建的高度,对很多赖以生存的需求方来说,说数据是命根子可能不为过,对数据的处理保证安全是第一位的,甚至需要“银行级合规”避免出现任何纰漏。
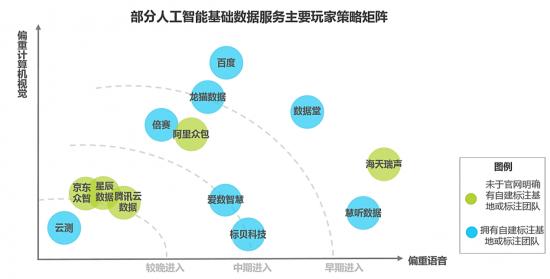
对巨头而言,出现安全问题就更加不能容忍,例如,百度数据众包为此在数据确权、数据加密、实名认证、生产监控等方面进行全流程管控确保数据安全(图片来源:网络):
如果我们翻开各大平台的官网主页,即便最新进入的玩家云测数据,都能发现它们用了很大的篇幅先讲安全。
不过,安全最终还是靠“不出事故”来检验,如同云计算稳定性说得再好,不宕机才是最好的证明。
2、“产量”:前沿科技下的密集的劳动力
虽然AI是顶尖的前沿技术,但AI数据确实一个不折不扣的劳动力密集行业。AI新基建首先驱动的是对数据产量的需求,这直接反应到劳动力规模是否足够大上,毕竟,一张一张的图、一句一句的话、一段一段的语音,都需要人力一个个标记好。
这是一个直观的要求,它的实现又分自有团队和代理全职团队两个部分,例如百度数据众包宣称自有2000人团队、遍布全球22个国家的超过5万名采标人员的代理商资源池——基本上,各平台都在着力凸显自己的团队规模,庞大的劳动力群体是AI新基建的获取足够多数据的重要保障。
但是,正如工厂流水线有最优生产流程,有帮助工人更快、更好完成工作的辅助工具一样,要提高产量、提升效率,流程和工具也必不可少,标准化、工业化的生产流程、高效易用的标注工具,也是百度等数据巨头提升自我的重要着力点。只不过,这些只是起到“乘数作用”,底子还是看劳动力规模。
3、质量:“精益制造”级别的复杂管理体系
在安全、产量之外,质量是数据众包成为一门可持续生意的根本,也是AI新基建真正落地的根本,质量不达标的数据不但不能推进系统识别能力的提升,甚至可能产生误导,如同学生学习了低劣的习题集再去考试一样。
而说白了,数据众包可以看作一门以数据为产品的“制造业”,要提升质量,对应地,就要配以“精益制造”级别的复杂管理体系。
这个体系,通常包括严苛的审核体系(例如标注、审核、抽检的层层把关)、人尽其用(不能混用CV、NLP等数据人员)、固定的例会总结问题提醒改进等,此外,还有一些工业化生产流程的浓重痕迹,例如百度数据众包平台的三阶段“生产加工流程”——小流量测试跑通生产流程、正式生产不断调优、交付时最终验收审核。
可以说,AI数据对质量的要求,和精细化制造业实现更好的良品率,别无二致。
数据众包,不止于AI新基建?
由于“劳动力需求”的特殊性,数据众包在特殊的时代背景下还超出了AI新基建的价值范围。
脱离行业角度,从稳就业来看,百度山西数据标注基地人员规模已近3000人,这些都是实实在在的就业人口容纳能力,是应届毕业生、其他行业分流人员(例如在山西的某传统产业)甚至包括残障人士的一份生计。加上其他工作人员,后疫情时期,一个数据众包平台已经帮助当地实现就业。百度方面表示未来要通过山西基地的示范作用,聚拢更多数据企业,为山西本地创造超过5万个就业岗位。
甚至于,百度数据众包还打算打通数据生产,数据交易和数据应用的三个环节,做一个开放的平台,如果这个构想成功,在AI数据领域建立一个资源对接的市场,不仅是AI新基建背后的数据生态闭环问题,或还将汇聚起大量的就业机会和新的经济增长点。
我们否定AI将摧毁就业机会时,理由常常是新的技术一定会带来新的工作岗位,而AI数据产业毫无疑问就是正在发生的例证。数据众包不仅将是一门更好的生意,也是下一个时代许多人的职业去处。
*本文图片均来源于网络
此内容为【智能相对论】原创,
仅代表个人观点,未经授权,任何人不得以任何方式使用,包括转载、摘编、复制或建立镜像。
部分图片来自网络,且未核实版权归属,不作为商业用途,如有侵犯,请作者与我们联系。


北京时间11月21日,百度发布第三季度财务报告,显示三季度营收达344.47亿元,归属于百度的净利润...
2023-11-21
10月17日,APUS出席百度世界大会2023。会上,百度公布了灵境矩阵业务进展,APUS作为灵境矩...
2023-10-20

2月28日,第六届CGL职场思辩者大型职场活动如约而至,本次活动由长江教育基金会学术支持。
2025-03-05



近日,京东宣布升级“春晓计划”,重磅推出“新商三步法”,包含“0元开店、拿补贴投广告、上专属活动”三...
2025-03-05

最新发布的2025年1月1日-3月2日销量榜单显示,问界M9和问界M7分别蝉联豪华SUV车型细分市场...
2025-03-05

投资家网(www.investorscn.com)是国内领先的资本与产业创新综合服务平台。为活跃于中国市场的VC/PE、上市公司、创业企业、地方政府等提供专业的第三方信息服务,包括行业媒体、智库服务、会议服务及生态服务。长按右侧二维码添加"投资哥"可与小编深入交流,并可加入微信群参与官方活动,赶快行动吧。






2016年注册于北京的中氢新能技术有限公司,下设位于大兴的装备制造公司、位于海淀区的技术研究院、材料...
一度无比高光的理想汽车,猝不及防遭遇重挫。
2024年1月10日,由投资家网主办,财经锐眼、有时间协办,北京微金科技有限公司承办的“第十二届股权...
2024年1月10日,由投资家网主办,财经锐眼、有时间协办,北京微金科技有限公司承办的“第十二届股权...
2024年1月10日,由投资家网主办,财经锐眼、有时间协办,北京微金科技有限公司承办的“第十二届股权...


投资家网(http://www.investorscn.com/)隶属于北京微金科技有限公司,是国内知名的资本与产业创新综合服务平台。平台聚集数百万优秀创业者、资深PE/VC、投资银行家、上市公司及实业高管、专家学者等,致力于构建起资本、产业与政府之间的桥梁与生态服务体系。
邮箱:bp@wefinances.com
微信:yangqin6060
微信:15201337588






Copyright © 投资家网 | 京ICP备16014291号-1 | 京公安备11010502031933号网站地图![]()

微博

微信公众平台