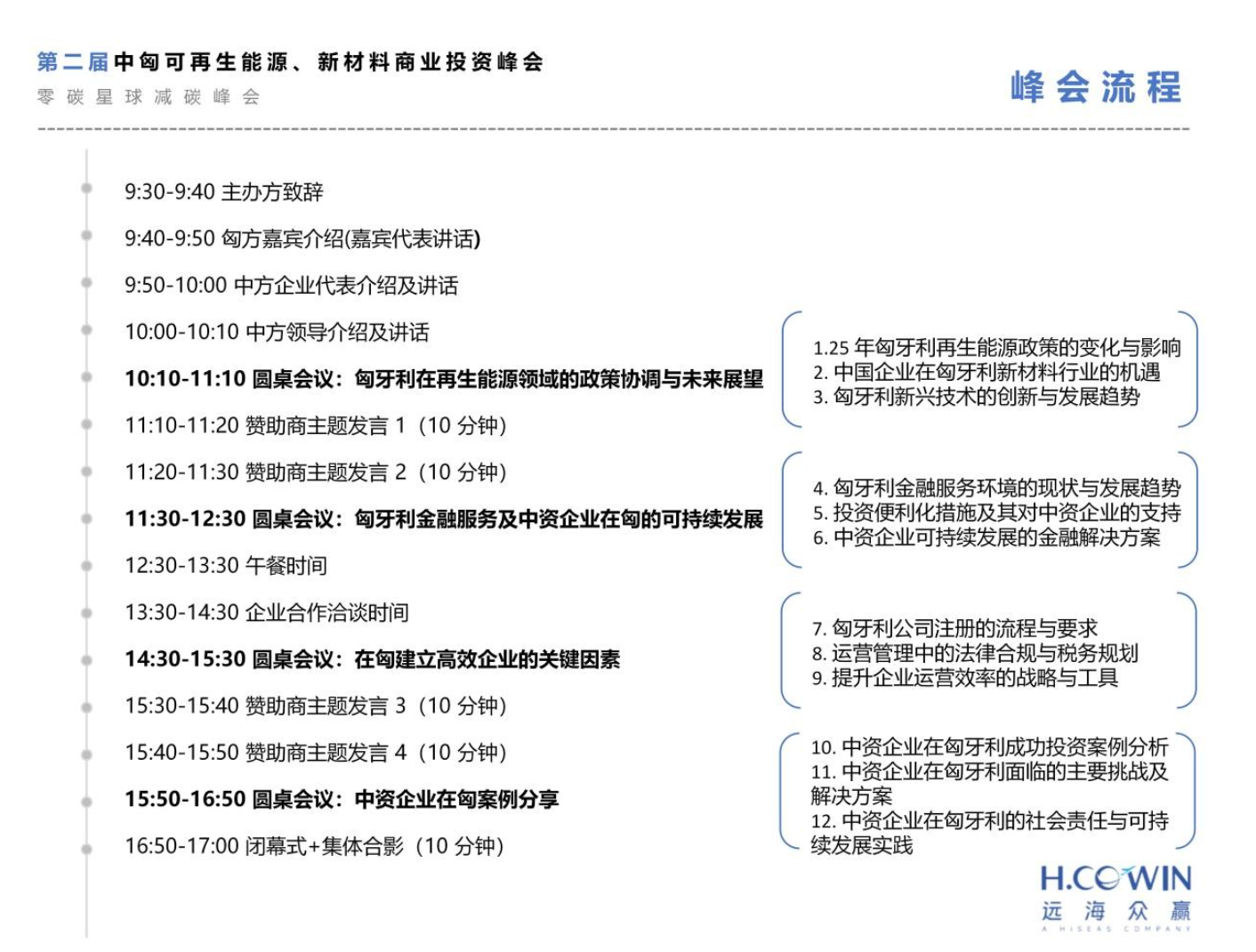
2023-05-22 15:29:17 来源:蓝驰创投 作者:
2023-05-22 15:29:17 来源:蓝驰创投 作者: 摘要:近日,潞晨科技宣布完成数亿元的A轮融资。
在2023年的整体规划上,尤洋说到,今年以来公司的业务量随着各行业客户的模型训练需求激增,预计收入整体相比去年会增长3-5倍。据了解,本轮融资后潞晨将加速扩张,并希望吸引招募更多的MLOps、AI大模型、AI框架等领域优秀人才加入,以更好服务客户。


1月13日,通化东宝(600867.SH)发布公告称,子公司东宝紫星(杭州)生物医药有限公司近日已成...
2025-01-13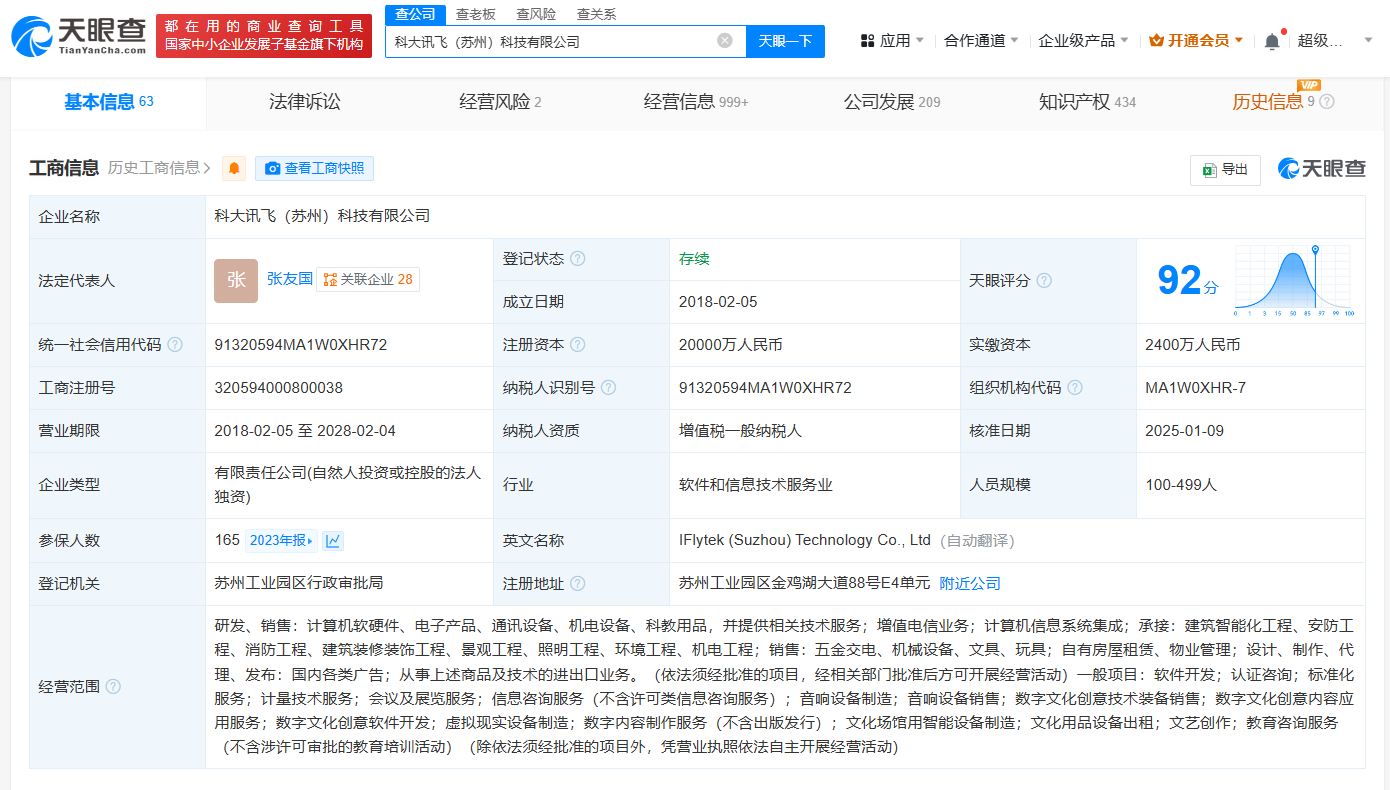
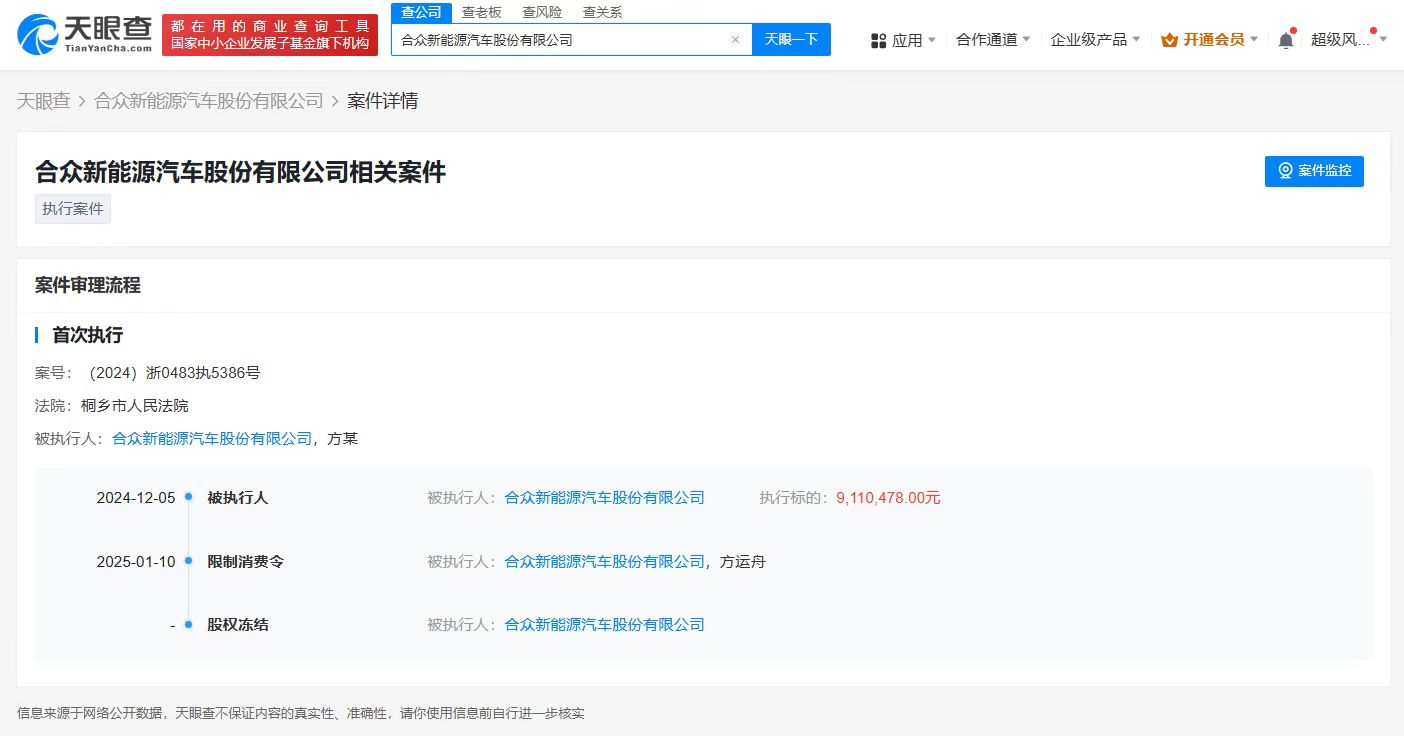
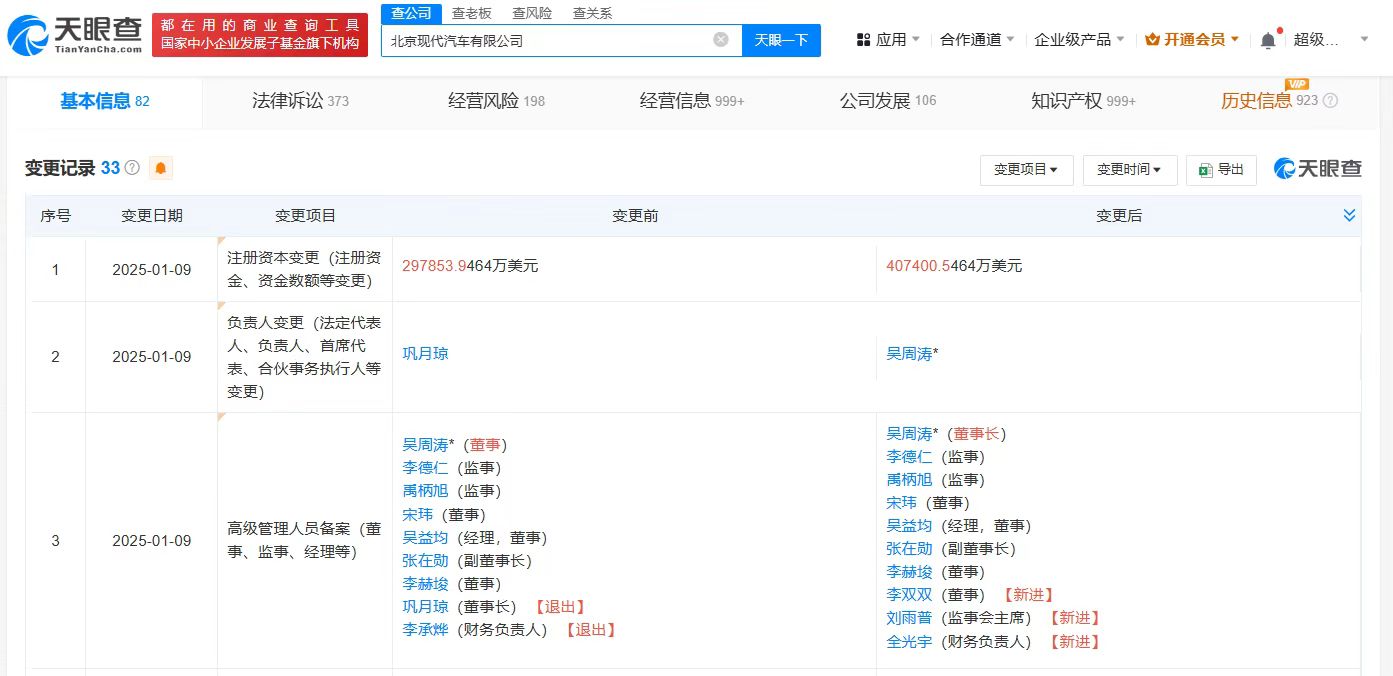


投资家网(www.investorscn.com)是国内领先的资本与产业创新综合服务平台。为活跃于中国市场的VC/PE、上市公司、创业企业、地方政府等提供专业的第三方信息服务,包括行业媒体、智库服务、会议服务及生态服务。长按右侧二维码添加"投资哥"可与小编深入交流,并可加入微信群参与官方活动,赶快行动吧。






2016年注册于北京的中氢新能技术有限公司,下设位于大兴的装备制造公司、位于海淀区的技术研究院、材料...
一度无比高光的理想汽车,猝不及防遭遇重挫。
2024年1月10日,由投资家网主办,财经锐眼、有时间协办,北京微金科技有限公司承办的“第十二届股权...
2024年1月10日,由投资家网主办,财经锐眼、有时间协办,北京微金科技有限公司承办的“第十二届股权...
2024年1月10日,由投资家网主办,财经锐眼、有时间协办,北京微金科技有限公司承办的“第十二届股权...


投资家网(http://www.investorscn.com/)隶属于北京微金科技有限公司,是国内知名的资本与产业创新综合服务平台。平台聚集数百万优秀创业者、资深PE/VC、投资银行家、上市公司及实业高管、专家学者等,致力于构建起资本、产业与政府之间的桥梁与生态服务体系。
邮箱:bp@wefinances.com
微信:yangqin6060
微信:15201337588






Copyright © 投资家网 | 京ICP备16014291号-1 | 京公安备11010502031933号网站地图![]()

微博

微信公众平台